[DB] 데이터 모델링이란?
(이글은 네이버 블로그 운영당시 작성한 글을 옮기었습니다. 따라서 2019년에 작성된 글입니다.)
1. 데이터 모델링의 이해
우리의 목적은 관계형 데이터베이스, 즉 표에 정보를 담는 것인데, 정보를 데이터베이스 표에 담는 것에 성공만하면 거대한양의 데이터를 데이터베이스가 가진 장점들을 활용하여 다룰 수 있게 되기 때문입니다.
하지만 무한히 거대하고 복잡한 현실을 정보로 만들어서 표에담는 것은 결코 간단하지 않습니다.
이러한 복잡한 현실을 데이터베이스화 시키는 것이 바로 데이터 모델링인데요.
따라서 데이터 모델링은 현실세계를 데이터베이스로 표현하기 위해서 우리는 추상화라는 것을 하게되고
그러기 위해서는 그 데이터와 관련된 업무파악을 해야합니다. 업무파악이 끝났으면 현실의 업무를 뜯어내서 개념을 찾아내야하고 각각의 개념들이 어떻게 상호작용하는지 알아야 합니다. (개념적 모델링)
이 과정에서 ERD(Entity Relationship diagram)을 도출하게 되죠.
*ERD란?
말 그대로 엔터티간의 관계를 그림으로 표현한 것을 말합니다.
ERD를 통해 만들고자 하는 모델링을 정확하게 도출해낼 수 있으며
업무관계자와의 커뮤니케이션에 있어 이해화 소통이 편해지기 때문에 ERD를 잘그리는 것은 중요합니다.
이제 그 개념을 관계형데이터베이스에 맞게 잘 구성을 해야합니다. 그것이 바로 논리적 데이터 모델링인데요,
각 테이블의 속성(column)과 식별자를 정의해주고 테이블과 테이블간의 관계를 모두 표현한 뒤 정규화하는 과정을
논리적 모델링이라고합니다.
이렇게 논리적 모델링을 거쳐 테이블을 이상적으로 잘그렸다면.
그 다음은 어떤 데이터베이스 제품을 쓸건지 선택하고 코드를 작성해서 실제 데이터베이스를 구축하는 것이 물리적 모델링단계입니다. 사실 논리적, 물리적은 기계적인으로 하는 부분이라서 실제로 개념적 데이터모델링이 중요하며 가장 실력자인 사람과 업무를 잘 이해하고 있는 사람이 함께 개념적 모델링을 하게 됩니다. (가장중요하니까요)
데이터 모델링의 정의, 특징, 단계를 정리하면 다음과 같습니다.
#데이터 모델링이란?
현실세계의 거대하고 복잡한 정보를 데이터베이스화 시키기 위한 과정으로 현실의 문제들을 체계적으로 수집하여, 사용자의 요구사항에 따라 모델링 표기법을 사용하여 표현하고 물리적으로 구현하는 과정.
#데이터 모델링의 특징
1. 추상화 : 데이터 모델링은 현실세계를 데이터베이스로 추상화하여 표현한 것이다.
2. 단순화 : 누구나 쉽게 이해할 수 있도록 표현한다
3. 명확성 : 명확하게 의미가 해석되어야 하고 한 가지 의미를 가져야 한다.
#데이터 모델링 단계
1. 개념적 모델링 : 업무를 분석하여 업무적 측면에서 모델링을 하되 전사적 관점으로 진행 한다.
(추상화 수준이 가장 높은 수준의 모델링임)
2. 논리적 모델링 : 데이터 베이스 모델을 정의한다.
속성(column)과 식별자를 정의하고 관계(relationship)를 모두 표현한다.
정규화를 통해서 재사용성을 높인다.
3. 물리적 모델링 : 구축할 데이터베이스 관리 시스템에 테이블,인덱스 등을 생성한다.
성능, 보안, 가용성 등을 고려하여 데이터베이스를 구축한다.
2. 데이터 모델링 용어와 각 용어의 개념
데이터 모델링에 대해서 이해가 되었다면 모델링할 때 쓰이는 용어들과 개념들에 대해서도 숙지할 필요가 있겟죠.
이전 [데이터베이스 with MySQL-1]에서 데이터베이스의 구성에서 다루었던 용어들이 데이터 모델링에서 사용되는 용어들입니다. 따라서 이를 좀 더 자세하게 알아볼건데요.
데이터 모델링을 할 때, 기본이 되는 엔터티(테이블,릴레이션), 속성(column),인스턴스(tuple,row), 기본키(PK),
외래키(FK), 도메인(domain), 개체 무결성, 참조 무결성 등 에 대해서 정리해보도록 하겠습니다.
2.1 엔터티(Entity) ≒ 테이블(table) or 릴레이션(Relation)
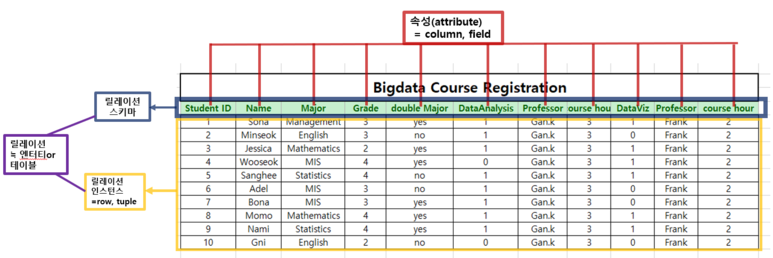
위 그림에서 볼 수 있듯이 정보가 저장될 수 있는 사람이나 장소, 사물 사건 등과 같이 업무에서 관리해야 할 데이터 집합을 의미합니다. 어떠한 개념, 사건, 장소 등의 명사로 구분됩니다.
지금 이표는 수강신청이라는 업무(개념)처리를 위해 관리되는 엔터티인 것이죠.
보통 ERD를 작성하는 개념적 모델링 단계에서 엔터티라고 하며 이러한 엔터티가 테이블 형태로 표현되고 릴레이션 스키마와 릴레이션 인스턴스로 구성된 것을 릴레이션이라고 말합니다.
엔터티, 릴레이션, 테이블 모두 비슷한 의미로 사용되지만 같은 단어는 아닙니다.
모든 릴레이션은 테이블이지만, 모든 테이블이 릴레이션은 아닙니다.
또한 엔터티는 표를 지칭하는 단어가 아니라 개념적 모델링 단계에서 추출해야 하는 대상을 가르키는 단어입니다. 즉 표를 가리키는 단어가 아닙니다.
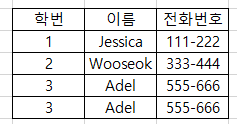
위의 표는 테이블이지만 릴레이션은 아닙니다. 릴레이션의 특성 중
"그 어떤 두개의 행도 동일하지 않다." 라는 조건을 위반하기 때문입니다.
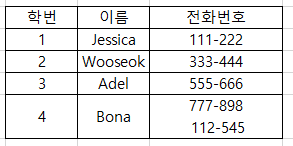
이 또한 테이블이지만 릴레이션이 아닙니다. 릴레이션의 특성 중
"테이블의 셀은 단일값을 포함한다" 라는 조건을 위반하기 때문이죠.
이러한 릴레이션(Relation)의 특징을 정리하자면 다음과 같습니다.
1. 행은 개체에 대한 데이터를 포함한다.
2. 열은 개체의 속성에 대한 데이터를 포함한다.
3. 한 열의 모든 항목은 동일한 종류다.
4. 각 열은 유일한 이름을 가진다.
5. 테이블의 셀은 단일 값을 포함한다.
6. 열의 순서는 중요하지 않다.
7. 행의 순서는 중요하지 않다.
8. 어떤 두개의 행도 동일하지 않다.
참조 : Codd, E.F의 "A Reational Model of Data for Larger Shared Databanks"의 논문
릴레이션 스키마란?
: 릴레이션 속성들의 집합을 의미합니다.
그럼 이제 엔터티에 대해서 정리한 것을 보도록 하겠습니다.
#엔터티의 의미
Peter Chen : 엔터티는 변별할 수 있는 사물이다.
James Martin : 정보를 저장할 수 있는 어떤 것이다.
C.J Date : 데이터베이스 내부에서 변별 가능한 객체이다.
Thomas Bruce : 정보가 저장될 수 있는 장소, 사람, 사건, 개념, 물건 등이다.
#엔터티의 특징
1. 식별자 : 엔터티는 유일한 식별자가 있어야 한다. (ex : 회원ID, 주민등록번호, 계좌번호, 학번 등...)
2. 인스턴스 집합 : 2개 이상의 인스턴스가 있어야 한다. (ex : 고객정보는 2명 이상 존재해야함)
3. 속성 : 엔터티는 반드시 속성을 가지고 있다. (ex : 고객이란 Entity는 회원ID, 패스워드,이름 등의 속성이 존재
4. 관계 : 엔터티는 다른 엔터티와 최소 한개 이상의 관계가 있어야 한다. (ex : 고객은 계좌를 개설한다.)
5. 업무 : 엔터티는 업무에서 관리되어야 하는 집합이다.
#엔터티의 종류
*유형과 무형을 기준으로 엔터티를 분류하면 다음과 같이 분류 할 수 있습니다.
|
종류
|
설명
|
|
유형 엔터티
|
- 업무에서 도출되며 지속적으로 사용되는 엔터티
(ex : 고객, 강사, 사원, 학생 등등..)
|
|
개념 엔터티
|
- 유형엔터티는 물리적 형태가 존재하지만, 개념 엔터티는 물리적 형태가 없음
- 개념적으로 사용되는 엔터티임
(ex : 조직, 보험 상품, 코스닥 종목, )
|
|
사건 엔터티
|
- 비즈니스 프로세스가 실행되면서 생성되는 엔터티
(ex : 주문, 체결, 취소주문, 신청 내역 )
|
*발생시점에 따라 엔터티를 분류하면 다음과 같이 분류할 수 있습니다.
|
종류
|
설명
|
|
기본 엔터티
|
- 키 엔터티라고도 함
- 다른 엔터티로부터 영향을 받지 않고 독립적으로 생성되는 엔터티를 말함
(ex : 고객, 강사, 사원, 학생 등 )
|
|
중심 엔터티
|
-기본 엔터티와 행위 엔터티 간의 중간에 있는 엔터티
- 즉, 기본 엔터티로부터 발생되어 행위 엔터티를 생성하는 엔터티
(ex : 계좌, 주문, 취소, 체결 등)
|
|
행위 엔터티
|
- 2개 이상의 엔터티로부터 파생된 엔터티
(ex : 주문 이력, 계좌이체 내역, 체결 이력 등)
|
2.2 속성(Attribue),인스턴스(Instance), tuple, row(행)
속성(Attribue) or Column(열), Field(필드)데이터 베이스를 구성하는 가장 작은 논리적 단위로서
더 이상 분리되지 않는 단위로 엔터티가 가지는 항목을 말합니다.
이것을 속성이라고도 하고 또는 컬럼, 필드라고도 부릅니다.
속성도 릴레이션과 마찬가지로 고유한 이름을 가지며, 동일한 릴레이션내에서는 같은 이름의 속성이 존재 할 수 업습니다. 그래서 우리가 이전 포스팅에서 CREATE TABLE문을 사용했을 때, 아래와 같은 에러를 겪은 것입니다.
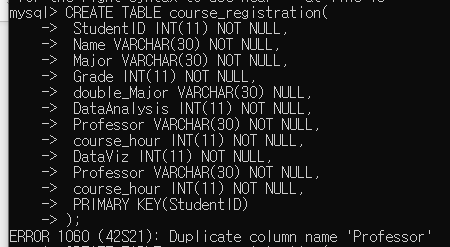
한 릴레이션안에서는 같은 이름의 속성이 존재할 수 없다.
이렇게 릴레이션을 구성하는 속성의 개수를 차수(Degree)라고 합니다. 따라서 우리가 사용했던 예제
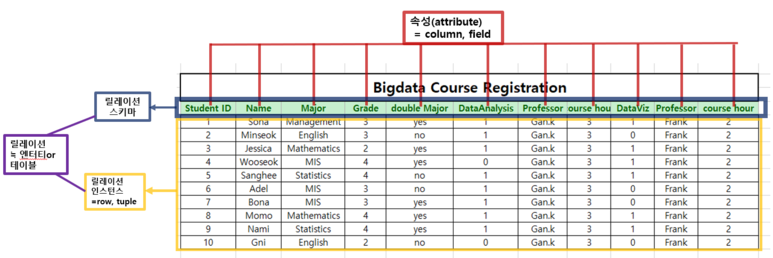
속성의 개수 = 차수(Degree) =11
위 표는 11차수라고 말할 수 있습니다.
튜플(tuple), 행(row), 인스턴스(Instance)
쉽게 우리가 테이블에서 하나의 행을 릴레이션에서는 튜플, 혹은 인스턴스라고도 부릅니다.
파일 구조에서 레코드와 같은 의미힙니다.
릴레이션이 현실세계의 어떤 엔터티를 표현한다면 튜플은 그 엔터티에 속한 구성원들 개개인의 정보를 표현합니다.
한 릴레이션에 포함된 튜플의 개수는 우리가 삽입,삭제 SQL문을 수행하면서 테이블의 크기가 달라졌던 것처럼 시간이 지남에 따라 변할 수 있으며 현재 구성하는 튜플의 수를 카디날리티(Cardinality, 기수)라고 합니다.
위 표의 카디날리티는 10줄이니까 10이네요.
도메인
도메인이란 릴레이션에 포함된 각각의 속성들이 취할 수 있는 같은 타입의 원자값(atomic)의 집합이라고 정의 되어있습니다. 예를 들면 프로그래멩 언어에서 변수를 선언할 때, 데이터 타입을 지정해주는 것처럼 데이터 모델링에서 또한 각각 속성들이 취할 수 있는 값을 본래 의도했던 값들만 저장되고 관리하기 위해서 설정해주는 것을 도메인 설정이라고 합니다.
결국, 간단하게 말하자면 도메인이란, 속성이 가질 수 있는 값의 범위입니다.
예를 들어, 성별이라는 속성이 있다면 이 속성은 남,여 라는 값만 가질 수 있도록 하는 것을 도메인 설정을 한다라고 합니다.
구체적으로 설명하자면, 데이터베이스 설계자가 성별이라는 속성(컬럼)의 도메인으로 'gender'를 정의하고 그 값으로 {1,2}를 지정 한뒤 성별이라는 속성은 'gender'도메인에 있는 값만 가질 수 있다고 지정해 놓으면 사용자들이 실수로 1,2 이외의 값을 입력하는 것을 DBMS가 막아줄 수 있게 됩니다.
2.3 관계(Relationship)
- 관계의 종류
관계(Relationship)는 엔터티 간의 관련성을 의미하며 존재 관계와 행위 관계로 분류됩니다.
존재 관계는 두 개의 엔터티가 존애 여부의 관계가 있는 것을 의미하고, 행위 관계는 두 개의 엔터티가 어떤 행위에 의한 관련성이 있다는 것을 의미합니다.
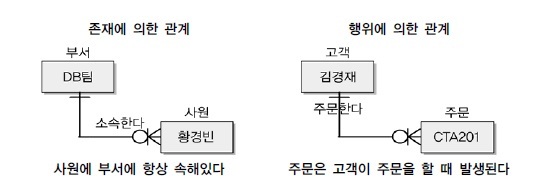
관계 차수
관계 차수(Relation Cardinality)는 두개의 엔터티 간의 관계에 참여하는 수를 의미합니다.
예를 들어 한명의 학생은 여러개의 강의를 신청할 수 있다. 이러한 경우는 1:N 관계가 되는데 이러한 관계차수를 정리하면 다음과 같습니다.
- 1:1 관계
1:1 관계는 엔터티의 인스턴스끼리 반드시 단 하나의 관계를 가지는 것을 말합니다.
예를 들어, 우리나라의 결혼제도는 일부일처제, 즉 한 남자는 한 여자와만, 역으로 한 여자도 한 남자와만 결혼을 할 수으며 남편을 또는 부인을 2명이상 둘 수 없는 관계 이러한 관계가 엔터티끼리 존재한다면 그 엔터티들의 관계는 1:1 관계입니다.
- 1:N 관계
1:N 관계는 한 쪽 엔터티의 인스턴스가 관계를 맺은 엔터티 쪽의 여러 엔터티 인스턴스를 가질 수 있는 것을 의미합니다. 매우 흔한 관계인데요 실제 DB를 설계할 때 자주 사용됩니다.
예를 들면, 부모와 자식관계라고 생각해본다면, 부모는 자식을 1명만 낳을 수도 있지만 2명,3명,4명 그 이상도 낳을 수 있습니다. 이를 1:N관게라고 합니다.
- N:M 관계
N:M(다대다)관계는 양쪽의 엔터티 모두 1:N 관계가 존재할 때 나타나는 모습입니다.
서로가 서로를 1:N 관계로 보고 있는 경우 입니다. 예를 들면, 한명의 학생이 여러개의 과목을 수강할 수 있고
반대로 한 개의 과목은 여러명의 학생이 수강합니다. 이러한 관계를 N:M관계라고 합니다.
* 필수적 관계과 선택적 관계
|
구분
|
설명
|
|
필수적 관계
|
- 반드시 하나가 있어야 하는 관계
- 'ㅣ'로 표현됨
ex) 고객은 반드시 하나의 계좌를 가지고 있어야 한다.
|
|
선택적 관계
|
없을 수도 있는 관계
- 'O'로 표현됨
ex) 고객은 있지만, 계좌가 없을 수도 있다면 선택적 관계가 됨
|
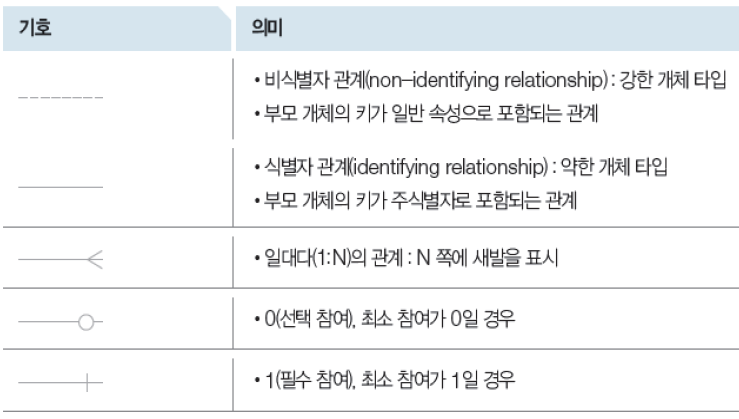
*식별관계와 비식별 관계
|
구분
|
설명
|
|
식별 관계
|
- A라는 엔터티의 식별자가 B라는 엔터티의 식별자 컬럼으로 참조 될 때
- 실선으로 표현됨
|
|
비식별 관계
|
-A라는 엔터티의 식별자가 B라는 엔터티의 식별자 컬럼이 아니라 일반 컬럼으로 참조 될 때
(단순히 외래키로 쓰일 때)
- 점선으로 표현됨
|
- 식별 관계의 예시

'계좌'라는 엔터티의 식별자인 계좌번호가 '계좌 입금' 이라는 엔터티의 기본키로 사용되어지므로 실선으로 표현되는데요, 이처럼 계좌 입금을 식별하기 위해서는 계좌번호가 없으면 식별이 안되기 때문에 이러한 관계를 식별 관계라고 합니다.
- 비식별 관계의 예시

'부서'라는 엔터티의 식별자인 부서코드가 '사원'이라는 엔터티의 기본키로 사용된 것이 아니라 일반 컬럼으로 사용되었습니다. 이처럼 사원을 식별하기 위해서 부서코드가 굳이 필요하지 않을 경우 이를 비식별 관계라고합니다.
관계에서 차수(1:1, 1:N, N:M), 필수&옵션, 식별&비식별을 ERD로 표현할 때 다음과 같이 표현합니다.
자 그럼 식별자, 기본키, 외래키라는 단어가 나왔는데 이러한 키들에 대해서 알아보도록 하겠습니다.
3. 식별자, 기본키, 외래키 그리고 참조무결성과 개체 무결성
식별자란?
식별자라는 것은 엔터티를 대표할 수 있는 유일성을 만족하는 속성(컬럼)을 말합니다. 보통 '키(Key)'라고 부릅니다.
보통 주민등록번호, 계좌번호, 외국인 등록번호, 여권번호 등이 유일성을 만족하기 때문에 식별자로서 사용됩니다.
이러한 식별자는 종류가 여러개가 있습니다. 하나씩 살펴볼게요
|
데이터베이스 키
|
설명
|
|
후보키
|
- 기본키가 될 수 있는 키들을 말함
- 릴레이션을 구성하는 속성들 중, 튜플을 유일하게 식별할 수 있는속성들의 부분집함
- 모든 릴레이션은 반드시 하나 이상의 후보키를 가져야함
- 릴레이션에 있는 모든 튜플들에 대해서 유일성과 최소성을 만족시켜야함
ex) '학생'이라는 릴레이션에서 '학번'이나 '주민번호'는 다른 튜플(row)을 유일하게 구별 할 수 있으므로 후보키가 될 수 있음
|
|
기본키
|
- 후보키 중에서 선택한 주키(Primary Key)
- Null 값을 가질 수 없음 (개체 무결성의 첫번째 조건)
- 동일한 값이 중복되어 저장될 수 없음 (개체 무결성의 두번째 조건)
|
|
대체키(보조키)
|
- 후보키가 둘 이상일 때 기본키를 제외한 나머지 후보키로 보조키라고도 함
ex) '학생'이라는 릴레이션에서 '학번'을 기본키로 정의하면 '주민번호'는 대체키가 됨
|
|
슈퍼키
|
- 한 릴레이션 내에 있는 속성들의 집합으로 구성된 키
- 모든 튜플들에 대해 유일성은 만족하지만, 최소성은 만족시키지 못하는 키
ex) '학생'릴레이션에서 학번+주민번호+이름으로 3개의 속성을 조합하여 슈퍼키를
만든 경우 다른 튜블과 구별이 가능하지만, '이름'이라는 속성이 단독으로 슈퍼키를 사용할 경우 구별이 가능하지 않기 때문에 최소성을 만족시키지 못함.
즉 뭉치면 유일성이 생기나 흩어지면 몇몇 속성들이 독단적으로 유일성있는 키로 사용되지 못하는 키(최소성을 만족못하는 키)
|
|
외래키
|
- 관계를 맺고 있는 릴레이션들 사이에서 데이터의 일관성을 보장해 주는 수단의 키
|
키에 대한 추가적인 설명과 함께 개체 무결성과 참조무결성에 대해서 설명을 위해서 이전 포스팅에서 두루뭉술하게 넘어갔던 예제를 다시 꺼내오도록 하겠습니다.
4.SQL 실습 : 학생들의 수강신청 데이터 모델링하기
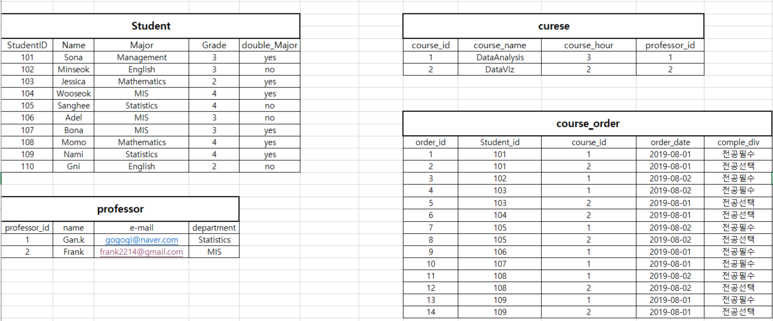
아래 엑셀파일은 우리가 이전 포스팅에서 사용했던 실습 엑셀파일입니다.
우선 실습에 필요한 엑셀파일을 첨부하겠습니다. 다운로드 받아주세요!
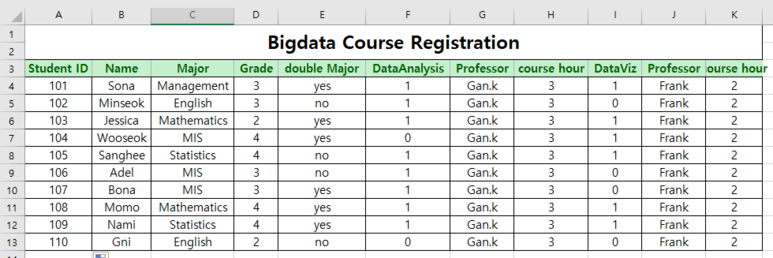
우리가 지난 시간에 다뤘던 테이블은 무엇이 잘못되었을까요?
만약에 이 학교에서 가르치는 과목이 지금 DataAnalysis와 DataViz 2과목만 있는 것이 아니라
100개의 강좌 또는 1000개의 강좌를 가르치고 있다고 생각해봅시다.
그러면 컬럼을 강좌수만큼 100개, 1000개를 늘려야하는데 각 강좌마다 강의시간이랑,담당교수도 옆에 컬럼으로 붙어 있으니 만약 1000개의 강좌를 더 추가해서 입력하려고 한다면 총 3천개의 컬럼을 더많을어야합니다.
즉 동일한 professor라는 컬럼을 쓸데없이 몇천개씩 만들어줘야 할겁니다. 저번에 제가 professor1,2로 했던 것을 몇천개씩 해줘야 하는 상황이 도래하는 것이죠. course_hour도 마찬가지고요.
(답도없죠...)
또 만약에 교수의 이메일과 소속학과를 추가하게 된다면요?

위 그림처럼 안그래도 교수이름이랑 강의시간이라는 속성들이 중복되고 있는데 이젠 이메일이랑 소속학과라는 속성의 데이터들 마저 중복이 됩니다. 또한 마지막 10번째 행(row)을 보시면 Gni라는 학생은 그 어떤 과목도 듣지 않는데, 학생으로 등록되었다는 이유만으로 해당 수업 신청내역에 데이터를 무조건 표시해야하는, 즉 없어도 될 데이터를 임의로 집어넣어줘야 하는 경우가 발생합니다.
(물론 이런 점은 RDB가 복잡해지면 어쩔 수 없이 발생할 수 있습니다만 최소화 해주어야 하는 부분이죠)
또 만약에 이후에수강신청한 과목의 이수구분을 넣어줘야 한다면?
미치는거죠, 컬럼이 감당못할정도로 많아집니다.
어떻게 하면 이러한 문제들을 해결하면서 데이터 베이스를 구축할 수 있을까요?
위에서 배운 모델링 내용을 토대로 함께 ERD를 작성해보면서 알아보도록 하겠습니다.
ERD 작성
ERD 작성을 쉽게 할 수 있는 ERD 툴은 여러개 존재합니다. 다만 저는 무료이면서 따로 설치없이 웹페이지에서 작성한 ERD에 따라 SQL문도 생성해주는 고마운 서비스를 이용하여 작성했습니다.
아래의 링크의 페이지를 이용하시면 ERD를 쉽게 작성할 수 있습니다.
https://www.erdcloud.com/

ERDCloud
Draw ERD with your team members. All states are shared in real time. And it's FREE. Database modeling tool.
http://www.erdcloud.com
ERD를 작성하는 절차는 다음과 같습니다.
1. 엔터티를 도출하고 배치한다.
우선 우리는 학생들의 수강신청을 처리하기 위해서 이 작업에서 도출될 수 있는 엔터티들을 생각해봐야 합니다.
엔터티를 도출해보면 학생, 교수, 과목, 수강신청내역 이렇게 4개를 도출 해볼 수 있겠네요.
학생, 교수, 수강과목은 기본엔터티로 볼 수 있고 수강신청내역은 행위 엔터티라고 볼 수 있겠네요
이게 바로 위에서 말했 듯이 엔터티는 사람,사물, 사건, 개념 등이 될 수 있다는 것을 느끼실 수 있겠죠?
2. 엔터티 간의 관계를 서술하고 설정한다.
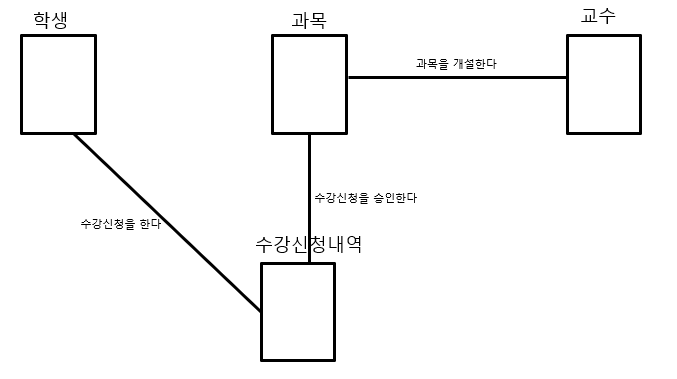
교수가 과목을 개설하면 학생은 수강신청을 통해서 해당 과목을 수강하게 됩니다.
그것을 그림으로 표현해보자면 위 그림처럼 표현 할 수 있겠죠?
3. 엔터티의 속성을 정의해주고 키를 설정해준다음, 관계 차수와 관계 필수(선택)여부를 표현한다.
엔터티를 도출했으면 그 엔터티의 속성들을 정의해주고 기본키를 설정해줍니다. 다음 관계차수(1:1인지 1:N인지 )를 표현해주고 필수(선택)여부도 표현해줍니다.
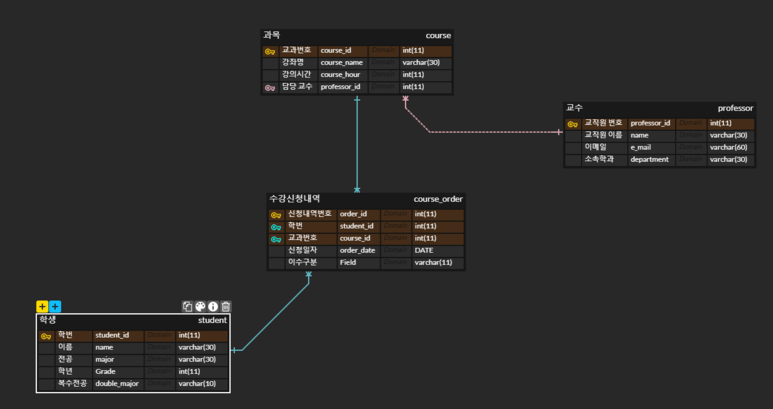
학생테이블은 학번으로 식별할 수 있으니 학번을 기본키로 설정해주고, 교수테이블은 교직원번호로, 과목은 교과번호로 기본키들을 설정해주었고요, 수강신청내역은 신청내역번호와 학번,교과번호 이 3개를 혼합(슈퍼키)해서 식별자를 만들어 주었습니다.
수강신청내역 테이블에는 이수구분이라는 속성도 추가시켜주었구요.
자 지금우리는 자연스럽게 ERD를 작성하면서 기존의 1개로 존재하던 테이블을 4개의 테이블로 쪼갰습니다.
이렇게 테이블을 쪼개개된다면 어떤 효과를 볼 수 있을까요?
직접 확인해보겠습니다.
테이블을 쪼개기전엔데이터 중복도 있고, 주황색으로 표시된 것처럼 임의 값도 문제가 많은 상태였습니다.

하지만 ERD에서 작성한 대로 테이블을 쪼갰더니 어떤가요?
중복되던 담당교수이름, 이메일, 강의시간, 담당교수 부서가 중복없이 저장되고 있습니다.
자 그럼 실제로 MySQL에서 ERD를 통해 도출해낸 데이터 모델을 구축하여 줍시다.
바로 지금 이것이 물리적 모델링이라고 생각하시면 됩니다.

|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
CREATE TABLE `student` (
`student_id` int(11) NOT NULL,
`name` varchar(30) NOT NULL,
`major` varchar(30) NOT NULL,
`Grade` int(11) NOT NULL,
`double_major` varchar(10) NULL
);
CREATE TABLE `course` (
`course_id` int(11) NOT NULL,
`course_name` varchar(30) NOT NULL,
`course_hour` int(11) NOT NULL,
`professor_id` int(11) NOT NULL
);
CREATE TABLE `professor` (
`professor_id` int(11) NOT NULL,
`name` varchar(30) NOT NULL,
`e_mail` varchar(60) NULL,
`department` varchar(30) NOT NULL
);
CREATE TABLE course_order(
order_id INT(11) NOT NULL,
student_id INT(11) NOT NULL,
course_id INT(11) NOT NULL,
order_date DATE NOT NULL,
comple_div VARCHAR(11) NOT NULL
);
ALTER TABLE `student` ADD CONSTRAINT `PK_STUDENT` PRIMARY KEY (
`student_id`
);
ALTER TABLE `course` ADD CONSTRAINT `PK_COURSE` PRIMARY KEY (
`course_id`
);
ALTER TABLE `professor` ADD CONSTRAINT `PK_PROFESSOR` PRIMARY KEY (
`professor_id`
);
ALTER TABLE `course_order` ADD CONSTRAINT `PK_COURSE_ORDER` PRIMARY KEY (
`order_id`,
`student_id`,
`course_id`
);
ALTER TABLE `course_order` ADD CONSTRAINT `FK_student_TO_course_order_1` FOREIGN KEY (
`student_id`
)
REFERENCES `student` (
`student_id`
);
ALTER TABLE `course_order` ADD CONSTRAINT `FK_course_TO_course_order_1` FOREIGN KEY (
`course_id`
)
REFERENCES `course` (
`course_id`
);
|
cs |
네, DROP TABLE 문으로 테이블을 잘 삭제가 되었구요.
해당 코드를 txt파일로 첨부해둘테니 필요하시면 다운받으시면 되겠습니다.
위 코드를 실행해주면
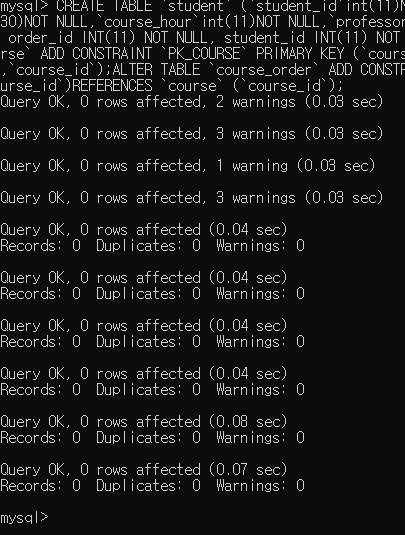
모든 코드가 에러없이 정상적으로 적용되었구요.
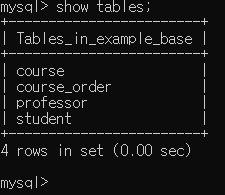
이렇게 4개의 테이블이 잘생성된 것을 확인 할 수 있습니다.
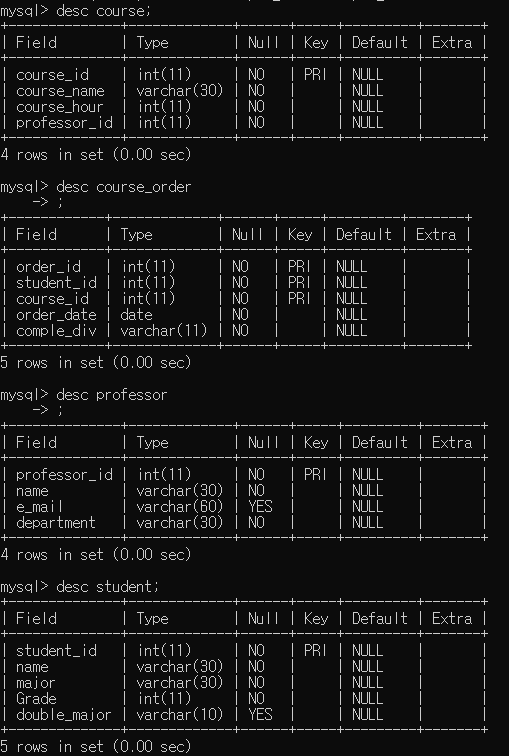
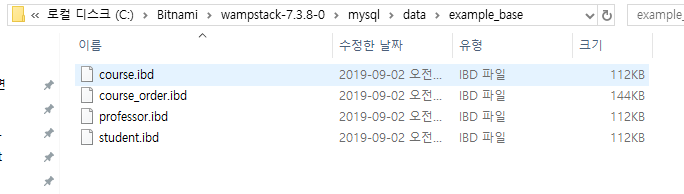
참고로 이렇게 테이블이 생성되면 데이터베이스 디렉토리안에 각각의 테이블 파일인 .ibd이 생성됩니다.
자 이번에도 마찬가지로 엑셀에 있는 데이터들을 DB화 시켜주도록 할게요.
우선 참조 무결성제약 조건때문에 student 테이블과 professor 테이블에 데이터를 우선적으로 삽입해준 다음
course 테이블의 테이터를 삽입시켜줘야합니다.
왜냐면 course 테이블에 professor_id는 외래키이기 때문인데요. 이렇게 다른테이블의 기본키가 외래키로 올 경우 다른 테이블의 기본키에 대한 데이터가 없는데 데이터를 삽입하려면 MySQL 입장에서는 뭘 참조해서 넣으라는거야?? 하면서 알수 없으니 새로운 데이터를 추가할 수 없다면서 에러를 보냅니다.
이러한 것이 바로 참조 무결성입니다.즉 참조할 수 없는 값을 외래키값으로 가질 수 없다는 것이 참조무결성의 정의입니다.
그럼 개체 무결성은 무엇일까요?
개체 무결성이란, 개체가 결점이 없음을 의미합니다. 결점이 없는 무결한 개체라는 것은
릴레이션을 구성하는 속성 중의 하나를 기본키로 지정하여 널(NULL) 값이나 중복된 값을 가질 수 없는 속성이, 즉 식별자가 언제고 어느때고 개체가 유일하다는 것을 식별하도록 하는 것이 개체 무결성 제약 조건입니다.
즉 학번이 동일한 학생, 주민등록번호가 동일한 상황은 모두 개체 무결성 조건을 위반한 상황이겠죠?
다행히 우리 주민등록번호는 개체 무결성 조건을 위반하지 않기 때문에 우리가 혼란에 빠지지 않고 민원처리를 할 수 있는거겠죠.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
load data infile '\student.csv' INTO TABLE example_base.student fields terminated by ','
(student_id,name,major,Grade,double_Major); #student 데이터 삽입
INSERT INTO professor (professor_id,name,e_mail,department)
VALUES (1,'Gan.K','gogogi@naver.com','Statistics'); #professor 데이터 삽입
INSERT INTO professor (professor_id,name,e_mail,department)
VALUES (2,'Frank','frank2214@gmail.com','Statistics'); #professor 데이터 삽입
INSERT INTO course (course_id,course_name,course_hour,professor_id)
VALUES (1,'DataAnalysis',3,1); #course 데이터 삽입
INSERT INTO course (course_id,course_name,course_hour,professor_id)
VALUES (2,'DataViz',2,2); #course 데이터 삽입
load data infile '\course_order.txt' INTO TABLE example_base.course_order fields terminated by ','
(order_id,student_id,course_id,order_date,comple_div); # course_order 데이터 삽입
# utf-8 테이블 설정 및 컬럼 설정 방법
ALTER TABLE course_order DEFAULT CHARSET=utf8; #테이블에 utf-8 설정
ALTER TABLE course_order MODIFY COLUMN comple_div VARCHAR(11) CHARACTER SET utf8 COLLATE utf8_general_ci; #컬럼에 utf-8설정
|
cs |
* load 하는 방법은 이전 포스팅에서 소개해드린 것과 동일합니다.
다만 이번에는 course_order 테이블을 보면 comple_div(이수구분) 컬럼의 데이터들이 한글이라서 csv파일로 저장할 때, utf-8설정을 해줘야하고 이 부분을 테이블과 컬럼에 반영해줘야 합니다. 그런데 utf-8설정을 하면 정확히 무슨 이유인지는 모르겠는데 csv파일을 잘 로드 못하길래 txt파일로 변환해서 load 시켜주었습니다. 이점만 참고하시면 데이터 삽입하시는데 문제 없을 겁니다.
혹시 필요하실까봐 SQL 코드를 파일첨부해드립니다. 필요하시면 다운받아 사용하시면 되겠습니다.
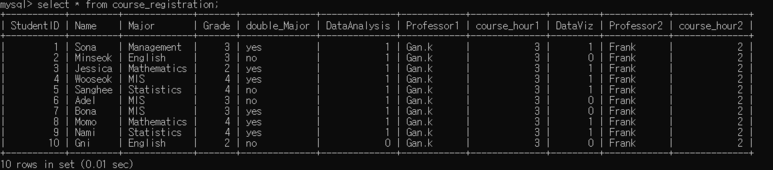
이제 그럼 4개의 테이블에 데이터들이 정확하게 다들어 갔는지 확인해보도록 할게요.
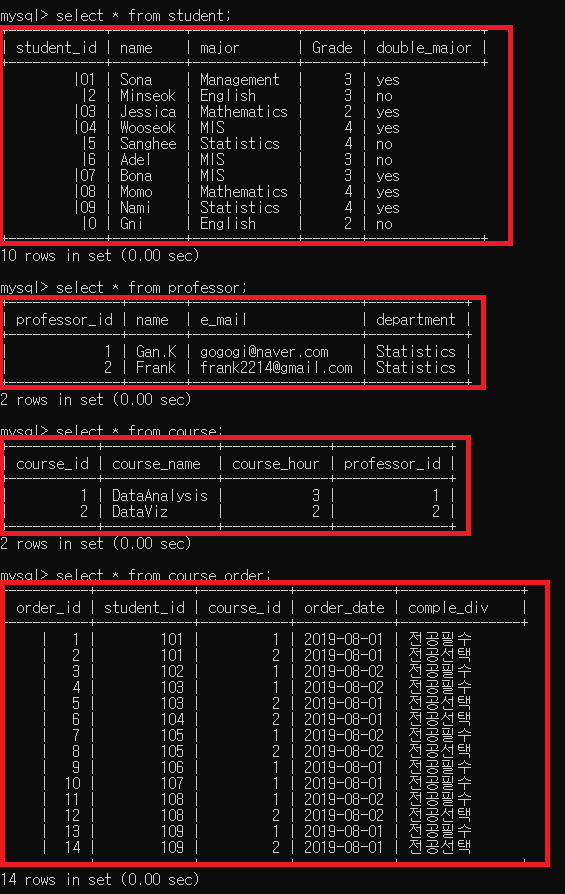
보이는 것처럼 4개의 테이블이 엑셀에 있는 것처럼 잘 들어 간 것을 확인 할 수 있습니다.
이로써 물리적 모델링까지 마쳤습니다. 우리는 이렇게 ERD 통해서 물리적 모델링까지 마치는 동안
알게모르게 정규화라는 개념을 사용했습니다.
다음 포스팅에서는 정규화의 의미 및 정규화 방법과 과정을 살펴보도록하며, 다양한 SQL 구문을 활용해보는 내용을 다루도록 하겠습니다.
정규화를 통해 데이터 모델의 성능을 끌어올리면서 다양한 SQL문과 SQL최적화원리에 대해서 다루면
데이터 베이스 개발자수준에서 필요한 내용들을 거의 모두 다루었다고 볼 수 있습니다.
그 이후는 자신이 계속 자주 사용해보고 여러 모델을 써보고 SQL문도 작성하면서 실력을 키워나가는 부분이고
혹시 데이터베이스 관리자라는 DBA가 되고 싶으시다면 OCP나 SQLP 자격증을 준비하는 것을 목표로 공부하시면 될 것 같습니다.