

Elasticsearch는 루씬(Lucene) 기반의 오픈소스 검색엔진이다.
Elasticsearch는 JSON 기반으로 문서를 저장하고 검색할 수 있으며 분석 작업도 가능하다.
Elasticsearch의 특징
1. 준실시간 검색 시스템
Elasticsearch는 실시간이라고 생각될 만큼 색인된 데이터가 빠르게 검색된다.
ES는 환경설정값에서 refresh_interval 이라는 것이 있는데 얼마나 빨리 검색될 수 있도록 할것인지를 설정할 수 있는 값을
기본값으로 1초로 지정되어있다.
2. 고가용성을 위한 클러스터 구성
한 대 이상의 노드로 클러스터를 구성하여 높은 수준의 안정성을 달성하고 부하 분산이 가능하다.
3. 동적 스키마 생성
RDB와는 다르게 입력될 데이터들에 대해 미리 스키마를 정의하지 않아도 동적으로 스키마 생성이 가능하다.
4. Rest API 기반의 인터페이스 제공
카프카(Kafka)같은 경우는 프로듀서, 컨슈머를 만들기 위해서 미리 구현된 라이브러리를 가져다쓰고 해야하지만
ES같은 경우는 그냥 Rest Client를 가지고 ES와 통신을 구현할 수 있다.
Elasticsearch 노드? 클러스터?
컴퓨터 용어의 사전적인 의미로 클러스터란 여러대의 컴퓨터들이 연결되어 하나의 시스템처럼 동작하는
컴퓨터들의 집합을 말한다.
"ES에서의 클러스터 => 노드들의 집합을 의미"
Elasticsearch에서도 여러 대의 노드(Node)들이 각자의 역할을 바탕으로 연결되어 하나의 시스템처럼 동작하게 되어있다.
따라서 클러스터의 성능이 부족하면 노드를 늘려서 대응할 수 있다. ( 단 모든 상황에서 적용되는 것은 아니다 )
노드(Node)라는 단어를 알아보자면, ES는 분산 시스템이며 노드는 이 분산 시스템에서 작동하는
하나의 ES 엔진(single server)을 의미한다.
노드는 ES에서 고유의 아이디값으로 UUID(Universally Unique Identifier)를 제공하며 원할 경우
노드의 고유의 아이디를 사용자가 직접 변경할 수 있다.
노드의 값을 변경하기 위해서 설치한 ES 위치의
config 디렉토리를 살펴보면 다양한 설정 파일들이 존재하는데 그중 elasitcsearch.yml 파일을 열어보면
node.name 이러한 값들을 설정할 수 있는 부분이 존재한다.
이렇듯 클러스터는 노드들의 집합을 의미하며 클러스터도 노드와 마찬가지로 고유의 이름으로 식별할 수 있으며
기본 클러스터 이름은 elasticsearch이다.
마찬가지로 클러스터의 이름을 변경하고 싶다면 elastcisearch.yml 파일에서 수정하면 된다.
노드(Node)의 종류
Elasticsarch의 클러스터는 여러개의 노드가 각자의 역할에 맞게 연결되어있다고 했다.
이러한 노드들은 Elasticsearch의 버전이 올라가면서 노드들의 역할은 계속 늘어나겠지만...
변하지 않는 것들 가장 기본적인 노드의 종류는 아래와 같다.
| 종류 | 역할 |
| 마스터 노드 | 클러스터 상태 관리 및 메타 데이터 관리 |
| 데이터 노드 | 문서 색인 및 검색 요청 처리 |
| 코디네이팅 노드 | 검색 요청 처리 |
| 인제스트 노드 | 색인되는 문서의 데이터 전처리 |
마스터노드와 마스터 후보 노드

마스터 노드는 딱 1대만 존재하고 마스터 노드가 죽으면 마스터 후보 노드들 중에서 새로운 마스터가 된다.
클러스터의 가장 큰 특징
1. 어떤 노드의 어떤 요청을 해도 동일한 응답을 준다는 점
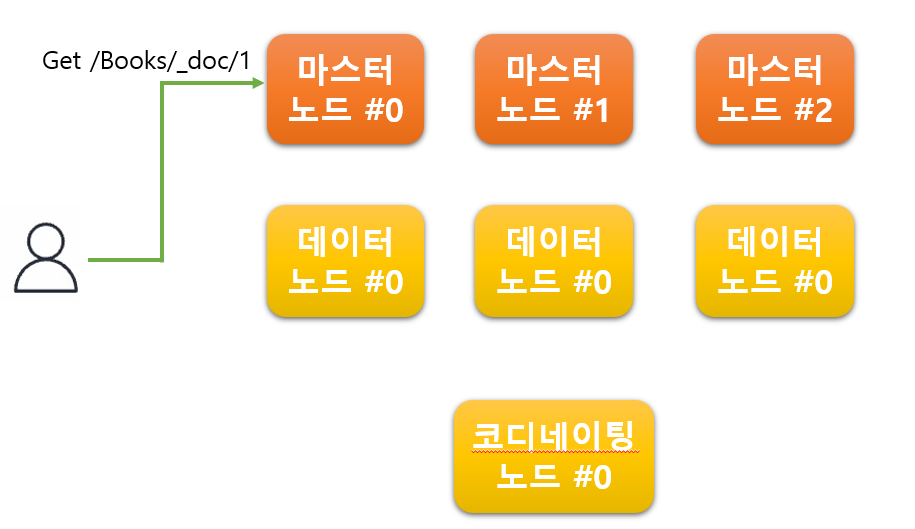
위 그림에서 의문점을 가질 수 있는게 문서의 색인 및 검색 요청을 처리하는 노드는 분명히 데이터 노드라고 했었는데
왜 요청을 마스터 노드에 하는 걸까? 라고 의문을 가질 수 있다.
위에서 언급했던 것처럼 Elasticsearch는 클러스터이기 때문에 어떤 노드에 어떤 요청을 해도
동일한 응답을 주기에 상관이 없다.
저렇게 마스터 노드가 Get 요청을 받으면 마스터 노드는 doc1 문서를 누가 가지고 있는지를 알고 있기 때문에
doc1 문서를 가지고 있는 데이터 노드에게 해당 요청을 전달하게 된다.
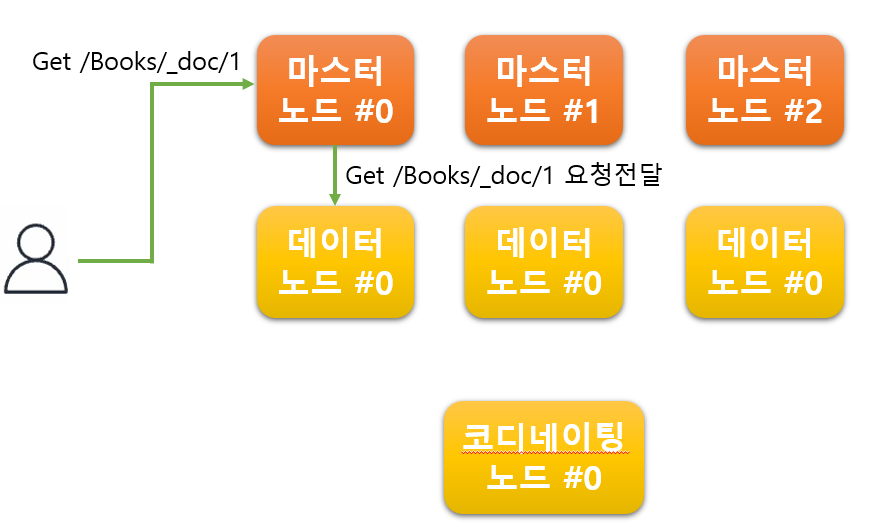
따라서 코디네이팅 노드에게 요청을 해도 잘작동하게되지만 이러한 경우 요청을 전달하기 때문에 발생하는
불필요한 트래픽이 발생하게 된다. 따라서 노드가 본연의 역할에 충실 할 수 있도록 구성하는 것이 중요하다.
그래서 가급적이면 데이터 노드에 대한 직접적인 접근을 차단한 뒤 로드벨런서를 두어서
로드밸런서를 통해서 통신할 수 있도록 하는 것이 좋다.
'ElasticSearch' 카테고리의 다른 글
| Elasticsearch 기본개념 정리 (2) : 인덱스와 샤드 (0) | 2023.02.12 |
|---|---|
| Elasticsearch 기본개념 정리 (3) : 매핑(Mapping)이란? (0) | 2023.02.11 |
| ElasticSearch - inculde (0) | 2022.11.02 |
| ElasticSearch - _delete_by_query 사용 (0) | 2022.03.16 |
| ElasticSearch - 필드 데이터 타입 확인하기 (0) | 2022.03.02 |