


- 들어가며
데이터 시각화는 통계학에 대한 전문적인 지식이 없을지라도
통계용어에 대한 개념적 이해가 바탕이 된다면 데이터를 시각화하면서 데이터를 효과적으로 분석하거나
설명할 수 있게됩니다.

여러분들 혹시 위 그림을 보면 통계학적 전문지식이 없기 때문에 그래프를 이해할 수 없으신가요?
전혀 아닙니다. 이처럼 우리는 알게모르게 통계적인 수치를 시각화하는 것을 배워왔습니다.
데이터를 시각화하는 것은 그 데이터를 잘 이해할 수 있도록 도와주며 이러한 시각화는 탐색적 분석을 하는데 매우 용이합니다.
(탐색적 분석이란 ? : 수집한 데이터를 이해하는 과정으로써 다양한 각도에서 관찰하여 이해하는 과정,
즉 데이터를 분석하기 전에 그래프나 통계적 방법으로 자료를 직관적으로 바라보는 과정 )
하지만 데이터의 복잡한 관계성을 효과적으로 표현하기 위해서는 막대그래프말고도 다양한 그래프가 존재합니다.
따라서 우리는 그러한 그래프들의 종류를 살펴보고
1. 각 그래프는 어떻게 읽고 해석해야하는지
2. 그래프들을 어떻게 그릴 수 있는지
이 2가지를 중점적으로 살펴보도록 하겠습니다.
다만 너무 기본적인 그래프, 예를 들면 기본 막대그래프, 꺾은선 그래프 등 초,중,고기본교육과정에서 배울 수 있는 정도의 그래프에 대해서는 따로 언급하지 않도록 하겠습니다.
그래프의 종류 및 해석
#상자그림(Box Plot)
아래 보이는 그래프가 바로 상자그림(box plot)인데요, 기본적으로 boxplot은
수집한 Data(자료)에서 얻은 5가지 수치 요약(five number summary)을 가지고 그립니다.
5가지 수치들은 다음과 같습니다.
1. 최솟값 : boxt에서의 최소값은 표본의 최솟값을 의미하는게 아닌 제 1사분위 - 1.5IQR입니다.
2. 제 1사분위(25%의 위치)
3. 제 2사분위(50%의 위치 즉, 중앙값 : Median)
4. 제 3사분위(75%의 위치)
5. 최대값 : 마찬가지로 제 3사분위 + 1.5IQR입니다.
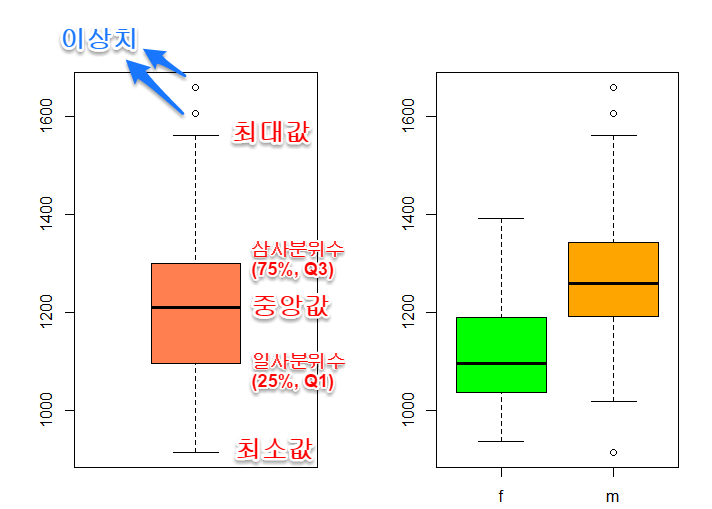
box plot 예시
예제를 보면서 IQR이 무엇인지 boxplot은 어떻게 그려지고 이 boxplot은 무엇을 의미하는지 살펴보겠습니다.

제가 임의로 1~10 사이의 수 100개와 1~10사이를 벗어나는 40,30,30,-10을 넣어 총 104개의 data를 만들었습니다. 그렇다면 이 자료에서 최대값은 40이고 최소값은 -10이겠죠.
하지만 box plot을 그릴 때 사용하는 최대값, 최소값은 IQR을 기준으로하는데요
IQR이란 제 3사분위 - 제 1사분위를 의미합니다.
따라서 104개에 대한 box plot을 그릴때 필요한 최대값, 최소값을 구하면 다음과 같이 구할 수 있습니다.
우선 사분위수를 구해준뒤 IQR을 계산해주면 되는데요.

사분위수
3사분위가 8이고 1사분위가 3.75네요. 즉 8-3.75=4.25가 IQR이됩니다.
box plot의 최대값은 3사분위 + 1.5*IQR이였죠? 그럼 8+(1.5*4.25) = 14.375이고
마찬가지로 최소값은 1사분위 - 1.5*IQR 그럼 3.75-(1.5*4.25) = -2.625가 됩니다.
이 최대 최소값을 구했으니 box plot을 그려주면
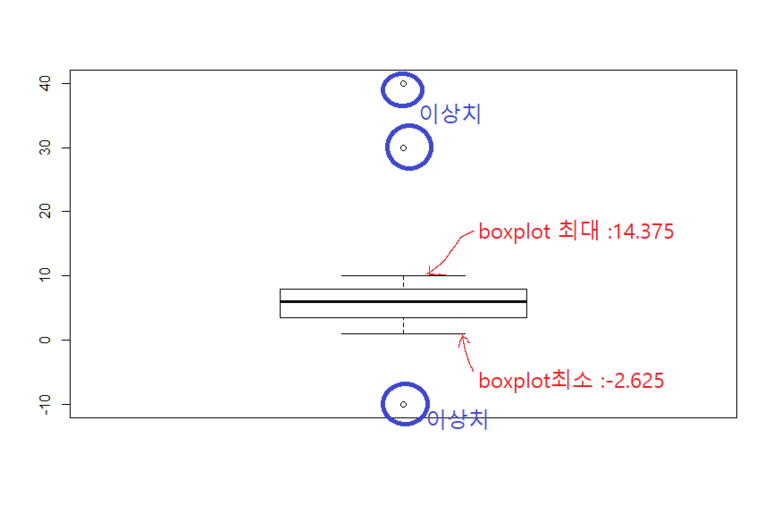
이처럼 그려지고 boxplot의 최대, 최소를 넘어가는 -10,30,30,40 들은 outlier(이상치)라고합니다.
이상치란 자료의 전반적인 범위에서 크게 벗어나는 즉,
데이터 전체 패턴에서 동떨어지는 값을 말합니다.
boxplot은 이러한 이러한 이상치를 확인하면서 자료의 대략적인 분포를 표현한 그래프입니다.
이상치는 데이터분석을 하는데 있어서 걸림돌이 되기 때문에 보통 대체값을 구해주거나 삭제한답니다.
#Scatter Plot (산점도)
box plot는 단변수(하나의 변수)를 시각화하는 그래프였다면, Sactter plot은 이변수(Bivirative)를 시각화하는 그래프입니다. boxplot과 scatter plot은 데이터 분석을 하는데 있어서 가장 기본적인 그래프라고 볼 수 있는데요.
이름처럼 각각의 관찰값들을 흩 뿌려놓은(scatter)모양을 하고 있으며 box plot과 마찬가지로 이상치를 찾을 수 있는 그래프입니다.
그리는 방법은 box plot과 달리 간단합니다. 해당 2개의 관찰값을 좌표상위에 찍기만 하면됩니다.
모든 관찰값들을 좌표상위 에 각각 표시만 해주면 되기 때문에 어렵지 않게 그릴 수 있습니다만 그렇기 때문에 이 그래프가 많은 정보를 제공해주지는 않습니다.

기업에 대한 만족도와 소비자의 지출에 대한 Scatter plot
해당그래프는 기업에 대한 x축은 어떤 특정 A기업에 대한 고객들의 지출 변수이고
y축은 그 특정 A기업에 대한 고객들의 만족도입니다.
해당 그래프를 통해서 우리는 간단한 사실을 알 수 있죠, 기업에 대한 만족도가 높으면 고객들은 더 많은 금액을 지출한다는 사실을 알 수 있습니다.
이렇듯 산점도는 각각의 두변수간의 상관성을 알 수 있고 대략적은 분포를 알 수 있습니다.
하지만

위 산점도처럼 상관관계도 없고, 자료들의 중앙분포가 무엇인지도 알 수 없는 그래프가 그려질 수 도있습니다.
이러한 점이 산점도의 단점이라고 볼 수 있겠으며 point가 겹치는 부분이 있을 수 있다는 것 또한 단점입니다.
물론 겹치는 부분은 jitter라는 기법 또는 투명도를 설정해준다거나 빈도에 따른크기 설정등으로 해결 할 수 있습니다.
#Strip chart : 띠그래프
띠 그래프, Strip chart는 표본의 크기가 작은 경우 상자 그림에 대한 훌륭한 대안으로 사용됩니다.
특히 그룹간의 비교분석을 하는 t검정, 분산분석 자료의 시각화를 하는 데 효과적이라고 하는데
여기선 t검정, 분산분석이 몰라도 됩니다.
boxplot은 그리게 되는 과정에서 boxplot의 최대,최소값 즉 lower limit, upper limit값에서 부터 제 1사분위, 제 3사분위 까지 약간의 표본으 그려지지 않을 수 있습니다. 즉, 그리다보면 표본의 손실이 약간 발생하게 됩니다.
하지만 띠 그래프는 그러한 표본의 손실없이 더 정확하게 그릴 수 있다는 점이 장점입니다.
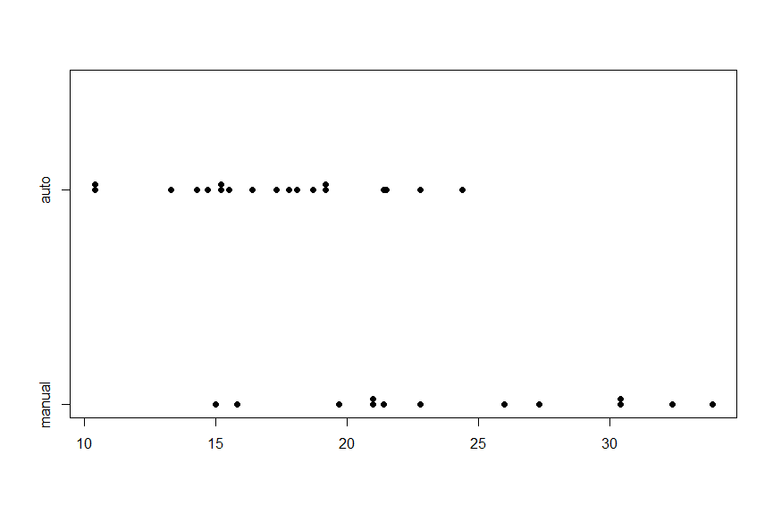
위 그래프는 기어가 오토인 자동차와 수동인 자동차의 연비에 대한 띠그래피입니다.
위 띠그래프처럼 각각의 띠그래프를 동시에 겹쳐그림으로써 우리는 수동기어인 자동차의 연비가 더 좋다는 것을 확인 할 수 있습니다.
#Mosaic plot(모자이크 플롯)
모자이크 플롯은 2개 이상의 범주형의 다변량 변수를 효과적으로 시각화 할 수 있는 그래프입니다.
모자이크 플롯의 사각형의 넓이는 각 범주에 속한 데이터의 수를 의미합니다.
만약에 다음과 같은 데이터가 있다고 가정해 보겠습니다.
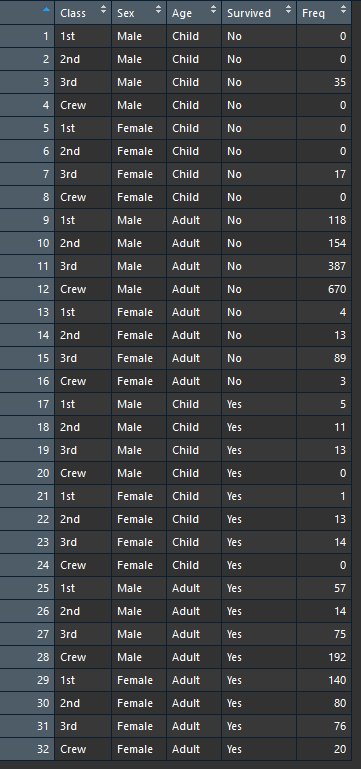
타이타닉에 생존자들에 대한 데이터인데요. class는 1등석, 2등석 등에 탑승한 사람들, Sex,age ,Survied는 생존여부 Freq는 명수입니다.
즉 첫번째 row를 보시면 1st이고 성별이 Male이며 나이가 child 인데 survived가 살아남지 못한 인원은 0명이라는 것인데요. 이를 통해서 보면 11번째 row는 3등급석에 탑승해서 살아남지 못한 성인남성은 387명이라는 이다.
라고 볼 수 있는데 이 많은 데이터들을 직관적으로 이해하기 위해서 모자이크 플롯을 그려보면 다음과 같습니다.

보기 좋게 생존한 사람은 빨간색으로 (yes라고한거보이시죠?), 생존하지 못한사람은 파란색으로 시각화했는데요!
위에서 언급했다시피 면적의 크기는 각 범주에 속한 개수를 뜻한다고 했으니
오른쪽에 가장큰 파란색 사각형을 보시면 Crew이고 adult이며 남성인데 사망한 사람이 가장 많다는 것이 바로 눈에 들어오게 됩니다.
그래프를 보니 대체적으로 어린아이와 여성이 우선적으로 구조되었기 때문에 생존했다고 표현된 크기가 크네요.
역시 괜히 영화로 나온게 아니네요!
#bubble chart 버블차트
버블차트는 산점도의 한 종류라고 볼 수 있는데요, 산점도는 이변량(2차원:변수가 2개)인 데이터의 분포를 시각화한 것이라면 버블차트는 2차원~4차원의 데이터셋을 시각화 할 수 있습니다
그리는 방법은 2개의 변수는 산점도와 동일한 방법으로 그리되 3번째 변수는 2개변수에 따른 나머지 변수의 크기에 따라 버블의 크기를 결정하여 그리면 됩니다.
만약 원의 크기를 x,y축에 사용했던 값으로 크기를 결정하면 2차원의 버블차트가 되는 것이고
원의 크기를 x,y축에 사용하지 않았던 다른 변수로 크기를 결정하면 3차원의 버블차트
3차원의 버블차트에 범주화된 정보를 담으면 4차원의 버블차트가 됩니다.
그럼 간단하게 버블차트를 하나 그려보도록 하겠습니다.
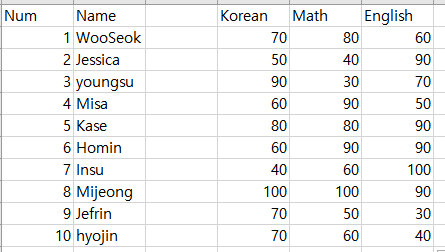
학생별 국어,수학,영어 성적표
위 표는 총 10명의 학생들이 3개 과목에 대한 성적표인데요 이 데이터 셋을 가지고
x축에는 국어성적, y축에는 영어성적, 그리고 버블의 크기는 수학성적으로 결정하여 학생별로 범주화하여 버블차르를 그려주면 다음과 같이 그려줄 수 있습니다.

학생별 과목성적에 대한 버블차트
성적은 고고익선이죠 ㅎㅎ, 따라서 1사분면 쪽에서도 오른쪽 맨 위쪽에 있는 학생들이 국어와 영어성적이 높은편인데 그 들중에서 버블의 크기가 큰사람은 수학성적이 더 높다는 것을 의미합니다.
결국 위 버블차트를 통해서 보면 'Mijeong'이라는 학생이 가장 성적이 훌륭한 것을 확인할 수 있습니다.
첨부파일
BubbleChart-k.html
#나이팅게일차트
백의의 천사로 알려진 나이팅 게일은 사실 실용적인 통계학자였습니다. 그녀는 '로즈 다이어그램'이라는 매우 훌륭한 데이터 시각화 사례를 남겼고 그것이 지금의 '나이팅게일 차트'라고 불려지고 있습니다.
나이팅게일이 전장에서 병사들을 치료하면서 전장에서의 부상으로인한 사망자보다, 병원의 열악한 위생환경으로 인해 사망하는 사람들이 더 많다는 것을 알게된 후, 이를 개선하기 위해서 예산을 마련하고자 글과 표를 이용해 이를 의회의원들에게 적극 알리고자 했다고 합니다.
하지만 전시 중에 글과 표만으로 의회의원들을 설득하기에는 부족했고 지원이 쉽게 이루어지지 않았는데 이때 나이팅 게일은 정보를 조금 더 효과적으로 전달하고자 하는 목적으로 만들었던 것이 바로 로즈다이어 그램 : Rose Diagram(나이팅게일 차트)입니다.

위 그림에서 보이는 나이팅 게일 차트의 언듯보면 파이차트와 매우 비슷하게 생겼습니다.
하지만 좀 더 살펴보면 원 1개는 1년을 의미하고 이는 다시 12개로 구성되어있는데 1개 1달을 의미합니다.
즉 각 조각은 1개월 단위로 사망자 현황을 보여주며 색깔은 사망 원인을 의미합니다.
그리고 면적은 해당 범주에 속한 관측값의 수를 의미합니다.
바깥쪽의 푸른색 = 전연병으로 인한사망
붉은색 = 전장에서의 치명적 부상으로인한 사망
검은색 = 기타 원인 사망
결국 위 그림으로 한눈에 2년의 사망원인을 파악하여 핵심을 단 한장에 표현할 수 있게됩니다.
이로써 나이팅게일은 전쟁중이지만 살 수 있는 전염병에 걸린 수많은 생명들을 살려낼 수 있게됩니다.
이러한 나이팅 게일차트를 응용하면 다변량 데이터를 평면에 표현할 수 있게되어 데이터를 직관적으로 이해하는데 도움이 됩니다.
이러한 나이팅 게일차트를 직접 데이터에 응용해보겠습니다.
우선 1975년 미국의 범죄 유형별 체포건수에 대한 데이터를 가지고 응용해보도록 하겠습니다.
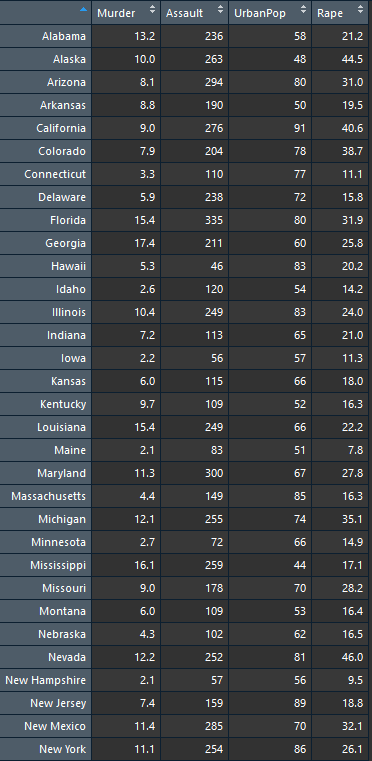
1975년 미국 범죄유형별 체포건수
각행은 도시이름이고
첫번째 column(열) Murder는 10만명당 살인범 체포건수
두번째 column(열) Assault 10만명당 폭행범 체포건수
세번째 column(열) UrbanPop는 도시 인구비율
네번째 column(열) Rape는 10만명당 강간범 체포건수
입니다. 이를 각 도시마다 나이팅 게일 차트를 그려준다면 범죄유형이 비슷한 도시를 파악할 수 있게됩니다!

자 오른쪽 맨아래에 보시면 Assult는 빨간색, Murder는 검은색, Rape는 파란색, Urbanpop는 초록색임을 확인 할 수 있고 이를 토대로 그래프를 살펴보면 대체적으로 폭행과 살인이 범죄의 주를 이루는 도시들,
NewMexico, NewYork,North Carolina,Mississippi 이 4개의 도시들은 범죄유형이 비슷한 도시라고 볼 수 있겠습니다.
이렇듯 나이팅 게일차트를 여러개를 그려서 시각화를 한다면 맨처음 나이팅 게일이 한 대상에 대한 데이터를 한눈에 파악하는 효과를 넘어서서 비슷한 유형의 대상을 찾아내는 용도로도 활용할 수 있게 됩니다.
즉 정리하면 나이팅게일 차트는 2가지 효과를 볼 수 있겠네요.
1. 평면에 다차원 데이터를 한눈에 파악하기 쉽게 표현할 수 있다
2. 이 나이팅게일차트를 여러개 그리면 대상의 유사성을 찾을 수 있다.
여기까지 데이터 시각화에 대해서 살펴보았는데요. 지금까지 소개해드린 시각화 방법말고도 정말 다양한 방법들이 존재합니다. 더 다양한 시각화 방법에 대해서 알고 싶으신분들에게 구글링해서 공부할 수 있도록 몇가지 keyword를 던져드리자면 인구 피라미드, 누적 막대 그래프, 상키 다이어그램, 3차원 산점도,지도 정보 시각화, 시계열 자료 시각화 등에 대해서 공부하시면 더욱 다양한 시각화 방법을 접하실 수 있을 겁니다.
시각화에 대해서 공부를 하시다보면 데이터 시각화를 잘하기 위해서는 결국 통계적 지식이 더욱 필요하다는 것과
이런 데이터에는 어떤 시각화를 해야지 의미전달이 효과적으로 이루어 질 수 있을까? 라는 고민을 하면서
데이터와 시각화 목적에 따라서 적절한 시각화 방법을 선택하는 안목을 기르는 것이 중요하다는 것을 느끼시게 될 겁니다.
끝으로 시각화를 하기위한 Tool들 중 오픈소스 tool 몇가지를 소개해드리고자합니다.
1. R 과 Phython : 기본적으로 데이터분석을 하기 위한 프로그래밍언어로 가장 잘알려진 이 두언어는 시각화를 위한 여러 라이브러리들이 존재하기 때문에 데이터분석을 하면서 시각화도 할 수 있습니다.
2. D3.js : 자바스크립트 라이브러리의 하나로서 자바스크립트를 어느정도 알고 계신분이라면 쉽게 이용하실 수 있을 것 같습니다. 저는 안써봐도 잘모르겠는데. 제가 소개해드리니는 영상에서도 많이들 쓴다고 하는 것 같네요.
3. tableauPublic : 원래 태블로는 유료프로그램이라서 있다는 것만 알고 깔아본적도 없는데, tableauPublic은 무료라고 하네요. 저도한번 설치해보고 써봐야겠어요 ㅎㅎ.
저는 데이터 시각화를 전문적으로 하는 dataviz specialist가 아니고 실제로 저는 R로만 시각화를 해보았기 때문에
어떤 Tool이 좋다 나쁘다를 말할 수가 없습니다.
다만 이러한 툴이 있구나 소개해드리고 여러분들이 직접 경험하시고 배우면서 익혀나가시면 좋을 것같구
툴에 대한 고민이나 현업에서의 데이터 시각화에 도움이 될 만한 영상을 소개해드리겠습니다.
'빅데이터' 카테고리의 다른 글
| [데이터 뉴스] - 기상 수치예보모델과 기상예보에 관해 (0) | 2020.08.28 |
|---|---|
| [데이터 뉴스] - 메뉴 코드 통합 안돼 배달 주문 빅데이터 활용 못하는 배민 (0) | 2020.08.28 |
| [빅데이터 기초5] - 빅데이터 분석 방법론2 - 데이터마이닝(DataMining)과 머신러닝(기계학습 :ML)의 차이 그리고 딥러닝에 대해 (0) | 2020.07.14 |
| [빅데이터 기초-번외] 앞으로 데이터 분석을 시작하려는 사람을 위한 책 (0) | 2020.07.14 |
| [빅데이터 기초4] - 빅데이터 분석 방법론1 - 통계분석 (요약통계,상관분석,회귀분석:선형회귀-Linear regression) (0) | 2020.07.14 |